Hochverfügbarkeit ist kein Feature das du einschaltest. Es ist eine Eigenschaft die sich erst zeigt wenn etwas schiefläuft.
In einem Projekt haben wir einen Go-Service betrieben der Traffic für eine globale AdTech-Plattform in Echtzeit attributiert. Jeder Request der Plattform durchläuft diesen Service, der ihm in unter 10ms Attributierungswerte zuweist damit Kampagnen korrekt getrackt und abgerechnet werden können. Fällt der Service aus bricht das Tracking ein, mit direkten Umsatzkonsequenzen für eine Plattform im neunstelligen Jahresumsatzbereich. Der Service war in EU und US deployed und verarbeitete täglich mehrere Millionen Requests.
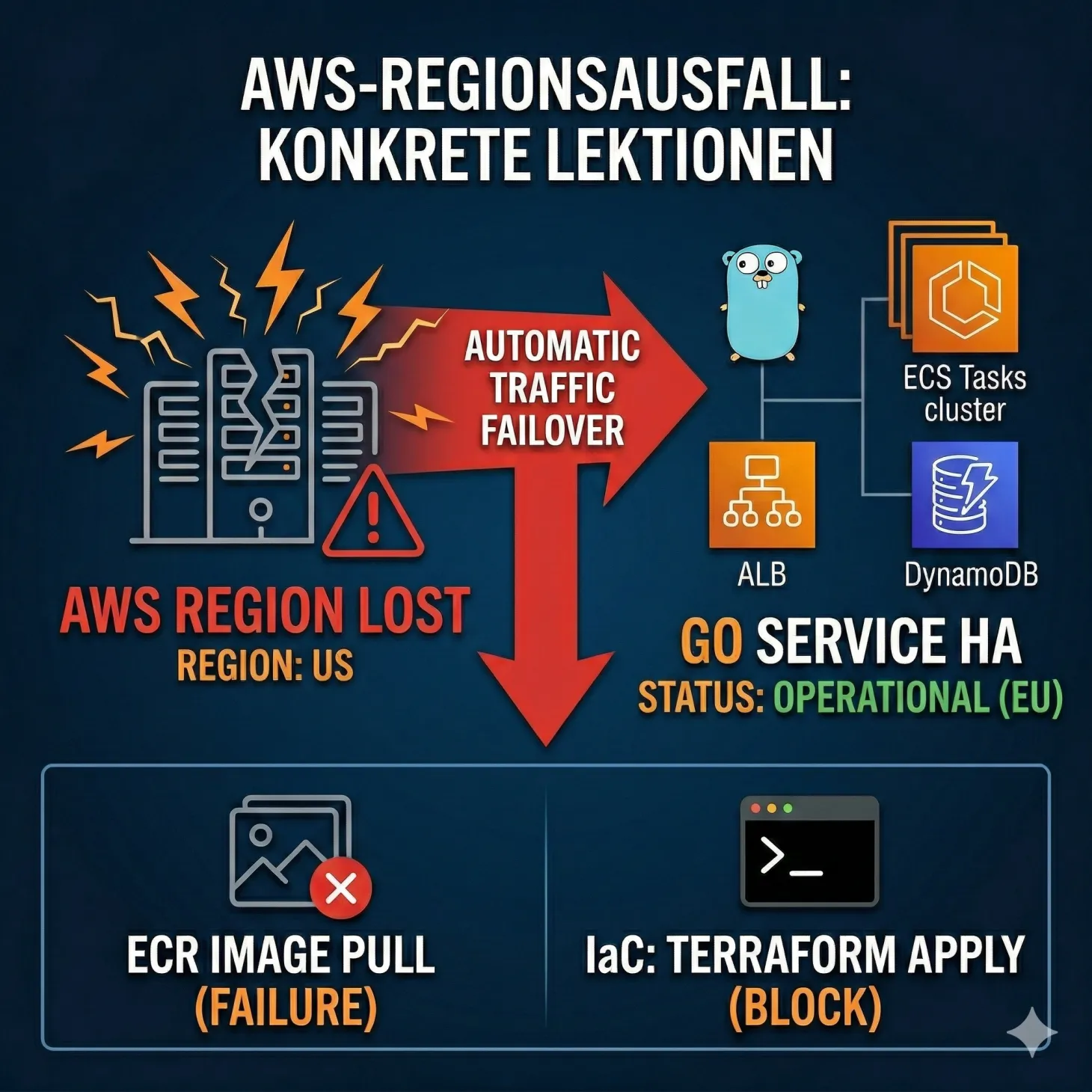
Vor einiger Zeit ist eine AWS-Region ausgefallen.
Der Service hat überlebt. Der Umsatz wurde nicht beeinträchtigt. Aber wir haben zwei versteckte Abhängigkeiten entdeckt die uns in einem ungünstigeren Moment teuer hätten werden können. Dieser Artikel beschreibt was passiert ist, warum es passiert ist und wie wir es gelöst haben.
Die Architektur: Warum wir so gebaut haben
Der Service attributiert Traffic für eine AdTech-Plattform. Das bedeutet konkret: Jeder Request der auf der Plattform eingeht, ob organischer Traffic oder bezahlte Kampagne, muss in Echtzeit einem Kanal zugewiesen werden damit Media Buyer ihre Kampagnen auswerten und optimieren können. Fehlt diese Zuweisung auch nur für einen Teil der Requests werden Kampagnen falsch bewertet, Budgets falsch allokiert und Umsatz nicht korrekt erfasst. Die Latenzanforderung von unter 10ms ist dabei nicht verhandelbar: Der Service sitzt im kritischen Pfad jedes einzelnen Requests.
Das hat unsere Architekturentscheidungen geprägt.
Wir haben uns bewusst für ein Primary-Secondary Multi-Region-Deployment entschieden statt für ein klassisches aktiv-aktiv. Der Grund war die Datenkonsistenz. Der Service vergibt täglich Werte aus einem gemeinsamen Pool. Würden beide Regionen gleichzeitig schreiben entstehen Race Conditions die zu doppelter Vergabe führen könnten. Das wäre schlimmer als ein kurzer Ausfall.
Die primäre Region ist die Single Source of Truth und die einzige die in die DynamoDB Global Table schreibt. Die sekundäre Region fragt zum Tagesbeginn per gRPC bei der primären Region an wenn neue Werte vergeben werden müssen. Bereits vergebene Werte werden in beiden Regionen über mehrere Cache-Layer lokal vorgehalten: In-Memory Cache für maximale Performance, Valkey für verteiltes regionales Caching.
Failover-Steuerung über Route 53 ARC
Das größte Risiko bei einem Primary-Secondary-Deployment mit geteiltem Schreib-Zugriff ist ein Split-Brain-Szenario: Beide Regionen glauben gleichzeitig die primäre zu sein und schreiben in die DynamoDB Global Table. Das würde zu inkonsistenten Daten führen, in unserem Fall zu doppelt vergebenen Attributierungswerten.
Um das zu verhindern steuern wir die Schreib-Hoheit über AWS Route 53 Application Recovery Controller. ARC ist eine hochverfügbare Kontroll-Ebene die außerhalb der verwalteten Regionen läuft. Das ist entscheidend: Im Ausfall-Szenario einer Region ist ARC nicht betroffen und kann zuverlässig signalisieren wann die sekundäre Region sicher vom Read-Only- in den Read-Write-Modus wechseln kann.
Der Failover-Ablauf ist damit klar definiert. Solange die primäre Region verfügbar ist bleibt die sekundäre Region im Read-Only-Modus und fragt per gRPC bei der primären an wenn neue Werte vergeben werden müssen. Fällt die primäre Region aus erkennt ARC den Ausfall und gibt der sekundären Region die Schreib-Hoheit. Es gibt zu keinem Zeitpunkt zwei Regionen die gleichzeitig schreiben.
AWS Global Accelerator sitzt vor beiden Application Load Balancern und leitet Traffic automatisch auf die verfügbare Region um sobald Health Checks einen Ausfall erkennen. In jeder Region laufen mindestens zwei ECS Tasks hinter dem ALB. Einzelne Task-Ausfälle innerhalb einer Region verursachen keine Downtime.
Was passiert ist
AWS Global Accelerator hat seinen Job gemacht. Health Checks haben den Ausfall erkannt, Traffic wurde automatisch von der ausgefallenen US-Region auf eu-central-1 umgeleitet. ARC hat die Schreib-Hoheit an die sekundäre Region übergeben. Keine manuelle Intervention, keine Downtime für Endnutzer. Die Automatisierungen haben gegriffen.
Dann wollten wir deployen.
Abhängigkeit 1: Das ECR Image
Unsere ECS Task Definition referenzierte ein Datadog Agent Image als Sidecar-Container für Monitoring und Observability. Dieses Image war in einem ECR Repository in us-east-1 gehostet. Die ECS Task Definition in eu-central-1 pullte dieses Image cross-region aus der ausgefallenen US-Region.
# Problematische Konfiguration
container_definitions = jsonencode([
{
name = "app"
image = "${var.aws_account_id}.dkr.ecr.eu-central-1.amazonaws.com/my-service:latest"
},
{
name = "datadog-agent"
# Image aus US-Region - versteckte cross-region Abhängigkeit
image = "${var.aws_account_id}.dkr.ecr.us-east-1.amazonaws.com/datadog-agent:latest"
}
])ECS konnte das Image nicht pullen. Neue Task-Instanzen konnten nicht starten. Deployments schlugen fehl.
Die laufenden Tasks waren nicht betroffen, ECS ersetzt laufende Container nicht automatisch. Aber jedes neue Deployment, jede Skalierung, jeder Container-Neustart hätte das Problem sichtbar gemacht.
Abhängigkeit 2: Terraform
Die naheliegende Lösung wäre gewesen die Task Definition per Terraform zu aktualisieren und das Image auf einen regionalen Pfad zu ändern. Aber auch das war nicht möglich.
Unser Terraform State lag sicher in eu-west-1 und war nicht betroffen. Aber beim terraform apply hat Terraform versucht den aktuellen Zustand der Ressourcen in us-east-1 abzufragen um Änderungen zu planen. Da die Region nicht erreichbar war schlug das Apply fehl.
Error: reading ECS Service: operation error ECS: DescribeServices
RequestError: send request failed
dial tcp: lookup ecs.us-east-1.amazonaws.com: no such hostWir konnten weder deployen noch die Konfiguration per Terraform ändern. Beide Werkzeuge die wir normalerweise verwenden waren von der ausgefallenen Region abhängig.
Das ist ein wichtiger Punkt der oft übersehen wird: Terraform plant Änderungen auf Basis des aktuellen Zustands der gesamten Infrastruktur. Ist auch nur eine Region nicht erreichbar kann Terraform keine sicheren Annahmen über den Gesamtzustand treffen und verweigert das Apply. Der State selbst spielt dabei keine Rolle.
Wir saßen in einer doppelten Abhängigkeit: Das ECR Image war nicht erreichbar und das Werkzeug um die Konfiguration zu ändern war es ebenfalls. Beide Probleme hatten klare Lösungen, aber sie mussten zuerst als systemische Schwachstellen erkannt werden.
Die Lösungen
ECR Cross-Region Replication
AWS ECR unterstützt automatische Cross-Region Replication. Images werden nach einem Push automatisch in konfigurierte Zielregionen repliziert.
resource "aws_ecr_replication_configuration" "main" {
replication_configuration {
rule {
destination {
region = "us-east-1"
registry_id = data.aws_caller_identity.current.account_id
}
destination {
region = "eu-central-1"
registry_id = data.aws_caller_identity.current.account_id
}
repository_filter {
filter = ".*"
filter_type = "PREFIX_MATCH"
}
}
}
}Nach der Replikation wurden alle ECS Task Definitions auf regionale Image-Pfade aktualisiert:
container_definitions = jsonencode([
{
name = "app"
image = "${var.aws_account_id}.dkr.ecr.eu-central-1.amazonaws.com/my-service:latest"
},
{
name = "datadog-agent"
# Jetzt regional - keine cross-region Abhängigkeit mehr
image = "${var.aws_account_id}.dkr.ecr.eu-central-1.amazonaws.com/datadog-agent:latest"
}
])Die IAM-Rolle der ECS Task Execution benötigt entsprechende Berechtigungen für den regionalen ECR-Zugriff:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ecr:GetDownloadUrlForLayer",
"ecr:BatchGetImage",
"ecr:BatchCheckLayerAvailability"
],
"Resource": "arn:aws:ecr:eu-central-1:ACCOUNT_ID:repository/*"
},
{
"Effect": "Allow",
"Action": "ecr:GetAuthorizationToken",
"Resource": "*"
}
]
}Terraform-Strategie bei Multi-Region-Infrastruktur
Für die Terraform-Abhängigkeit gibt es keine perfekte Lösung, aber es gibt Strategien die das Risiko reduzieren.
Die effektivste ist die Trennung der Terraform-Workspaces nach Region. Statt einer gemeinsamen Konfiguration für alle Regionen bekommt jede Region einen eigenen Workspace mit eigenem State. Ein terraform apply für eu-central-1 greift dann nur auf Ressourcen in eu-central-1 zu und ist vollständig unabhängig von us-east-1.
Die Verzeichnisstruktur dafür ist straightforward:
infrastructure/
├── modules/
│ ├── ecs-service/
│ ├── alb/
│ └── ecr/
├── regions/
│ ├── eu-central-1/
│ │ ├── main.tf
│ │ ├── variables.tf
│ │ └── backend.tf
│ └── us-east-1/
│ ├── main.tf
│ ├── variables.tf
│ └── backend.tf
└── global/
├── ecr-replication/
├── global-accelerator/
└── route53-arc/Jede Region verwendet dieselben Module aber hat einen eigenen State und kann unabhängig deployed werden. Globale Ressourcen wie Global Accelerator, ECR Replication und Route 53 ARC liegen in einem separaten global Workspace der nur bei Änderungen an der globalen Infrastruktur angefasst wird.
Zusätzlich empfiehlt sich die Dokumentation von AWS CLI Befehlen für kritische Notfall-Szenarien die auch ohne Terraform ausgeführt werden können. Im Ausfall-Szenario ist keine Zeit um Befehle nachzuschlagen. Was nicht vorbereitet und getestet ist existiert im Notfall nicht.
Global Accelerator: Was funktioniert hat
Es wäre unfair nur über die Lücken zu schreiben. AWS Global Accelerator hat in diesem Szenario genau das getan wofür er gebaut wurde.
Die Konfiguration war straightforward: Zwei Endpoint Groups, eine pro Region, mit Health Checks auf den ALB Health Check Endpoint. Traffic Dial auf 100% für beide Regionen im Normalbetrieb.
resource "aws_globalaccelerator_accelerator" "main" {
name = "my-service-accelerator"
ip_address_type = "IPV4"
enabled = true
}
resource "aws_globalaccelerator_listener" "main" {
accelerator_arn = aws_globalaccelerator_accelerator.main.id
protocol = "TCP"
port_range {
from_port = 443
to_port = 443
}
}
resource "aws_globalaccelerator_endpoint_group" "eu" {
listener_arn = aws_globalaccelerator_listener.main.id
endpoint_group_region = "eu-central-1"
traffic_dial_percentage = 100
health_check_path = "/health"
health_check_protocol = "HTTPS"
health_check_interval_seconds = 10
threshold_count = 3
endpoint_configuration {
endpoint_id = aws_lb.eu.arn
weight = 100
}
}
resource "aws_globalaccelerator_endpoint_group" "us" {
listener_arn = aws_globalaccelerator_listener.main.id
endpoint_group_region = "us-east-1"
traffic_dial_percentage = 100
health_check_path = "/health"
health_check_protocol = "HTTPS"
health_check_interval_seconds = 10
threshold_count = 3
endpoint_configuration {
endpoint_id = aws_lb.us.arn
weight = 100
}
}Der Health Check Interval von 10 Sekunden und ein Threshold von 3 bedeutet dass Global Accelerator innerhalb von 30 Sekunden auf einen Ausfall reagiert. Für einen Service der direkt Umsatz beeinflusst ist das akzeptabel. Wer schnellere Reaktionszeiten braucht kann den Interval auf 30 Sekunden mit einem Threshold von 1 reduzieren, muss aber mit mehr False Positives rechnen.
Checkliste: Regionale Isolation
Nach diesem Incident haben wir eine systematische Checkliste für Multi-Region Deployments entwickelt die ich jedem empfehle der aktiv-aktiv oder Primary-Secondary über mehrere Regionen betreibt.
Failover-Steuerung
Ist die Schreib-Hoheit über eine externe Kontroll-Ebene wie Route 53 ARC gesteuert? Ist der Failover-Ablauf dokumentiert und getestet? Gibt es ein Split-Brain-Szenario das durch gleichzeitiges Schreiben entstehen könnte?
Container Images
Alle ECR Repositories mit Cross-Region Replication konfiguriert? Alle Task Definitions auf regionale Image-Pfade aktualisiert? Auch Third-Party Images wie Monitoring Agents, Service Mesh Proxies, Security Sidecars überprüft?
Terraform und IaC
Sind Terraform Workspaces nach Region getrennt? Gibt es dokumentierte AWS CLI Befehle für kritische Notfall-Szenarien? Wurde ein Apply während eines simulierten Regionsausfalls getestet?
Secrets und Konfiguration
Alle Secrets in AWS Secrets Manager in jeder Region vorhanden? Parameter Store Werte regional repliziert? Keine hardcodierten regionalen Endpoints in der Konfiguration?
Deployment-Pipeline
CI/CD-System hat Zugriff auf beide Regionen unabhängig voneinander? Build-Artefakte in regionalen S3-Buckets? Deployment kann in jede Region unabhängig ausgeführt werden?
Monitoring und Observability
Monitoring-Agents können regional starten ohne externe Abhängigkeiten? CloudWatch Dashboards für jede Region separat konfiguriert? Alerting funktioniert auch wenn eine Region ausgefallen ist?
Failover-Test
Wurde ein regionaler Ausfall aktiv simuliert? Nicht nur Traffic-Failover testen sondern auch Deployment, Skalierung und Container-Neustart in der verbleibenden Region?
Die eigentliche Lektion
Die Architektur hat gehalten. Route 53 ARC hat die Schreib-Hoheit sauber übergeben, Global Accelerator hat den Traffic umgeleitet, die Cache-Layer haben die sekundäre Region am Leben gehalten. Das System hat genau das getan wofür es gebaut wurde.
Aber ein Regionsausfall zeigt immer mehr als du erwartest. In unserem Fall zwei Abhängigkeiten die unter normalem Betrieb unsichtbar waren: ein Monitoring-Image in der falschen Region und eine Terraform-Konfiguration die bei partiellen Ausfällen versagt.
Beide Probleme waren lösbar. Beide wären vermeidbar gewesen. Und beide hätten in einem ungünstigeren Moment, einem notwendigen Hotfix mitten im Ausfall, echte Konsequenzen gehabt.
Multi-Region-Deployments sind kein einmaliges Architekturprojekt. Sie sind ein laufender Prozess der regelmäßig hinterfragt werden muss. Nicht die Anwendung selbst, sondern alles was benötigt wird um sie zu betreiben: Container-Registries, Deployment-Pipelines, IaC-Tooling, Monitoring. Jede neue Abhängigkeit die ohne regionale Isolation eingeführt wird ist eine versteckte Lücke die auf ihren Moment wartet.
Ein simulierter Regionsausfall in einer Nicht-Produktionsumgebung ist der einzige zuverlässige Weg diese Lücken zu finden bevor AWS es für dich tut.