Mai. Zwei Wochen vor der Hochsaison.
Die Suchlatenz hatte die Fünf-Sekunden-Marke überschritten.
Nicht P95. Nicht der Worst Case.
Median.
Der Traffic stieg wie jedes Jahr. Wenn die ersten warmen Wochenenden kommen verdoppelt sich das Suchvolumen innerhalb von Tagen, Redakteure pflegen strukturierte Daten kontinuierlich, und das System muss beides gleichzeitig stemmen. Was jahrelang gut genug war wurde plötzlich zum langsamsten Teil der gesamten Plattform. Ich betrieb Sphinx. Es hatte gute Dienste geleistet – bis die Anforderungen es überholten.
Wenn "funktioniert" aufhört zu skalieren
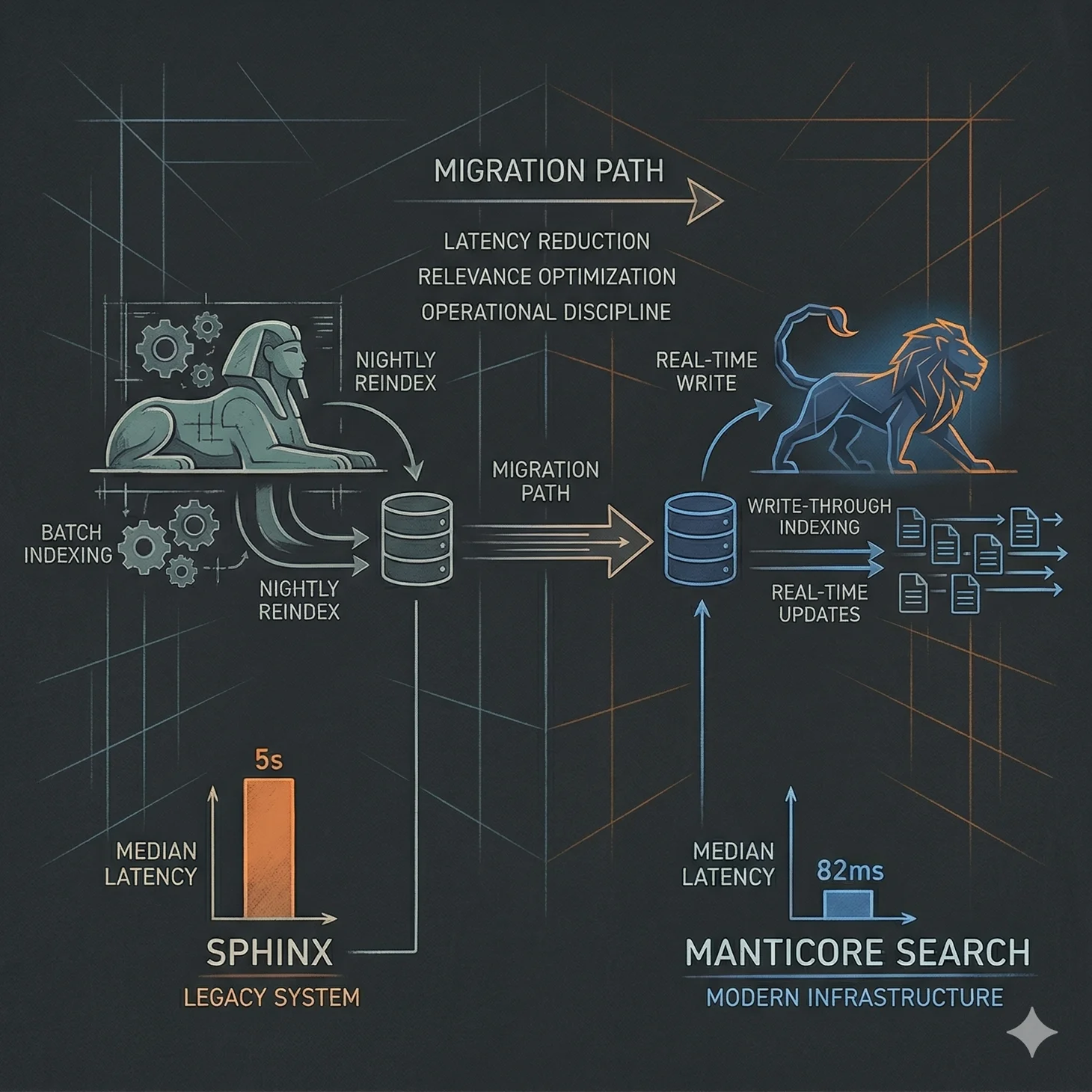
Das ursprüngliche Setup war konventionell und hatte sich über Jahre bewährt. MySQL als Source of Truth, Sphinx für die Volltextindizierung, PHP-FPM als Application Layer, ein nächtlicher Full-Reindex und ein Delta-Index alle 15 Minuten. Jahrelang lag die mediane Suchlatenz zwischen 300 und 500 Millisekunden – akzeptabel für eine redaktionell betriebene Plattform mit saisonalem Traffic.
Dann änderten sich drei Dinge gleichzeitig. Das Content-Volumen verdoppelte sich innerhalb von 18 Monaten. Ich führte facettierte Filterung ein – nach Hersteller, technischen Spezifikationen und Baujahr. Und Redakteure begannen strukturierte Metadaten kontinuierlich statt in Batches zu aktualisieren. Jede dieser Änderungen wäre für sich genommen handhabbar gewesen. Zusammen trafen sie eine Architektur die für genau dieses Nutzungsmuster nicht ausgelegt war.
Die Symptome kamen schleichend. Der Delta-Index lief den Writes hinterher. Merge-Zeiten stiegen. Memory-Druck baute sich auf. Gelegentliche Query-Spitzen von drei bis fünf Sekunden tauchten auf ohne erkennbaren Auslöser. Das eigentliche Problem war dabei nicht rohe Performance – es war operative Fragilität. Reindizierung wurde ein Ereignis das ich planen musste. Deployments mussten um Indexierungs-Jobs koordiniert werden. Suche hörte auf Infrastruktur zu sein und wurde Zeremonie. Das war die Architektur-Grenze.
Warum Manticore und nicht Elasticsearch
Elasticsearch war die offensichtliche Alternative. Ich habe sie aus pragmatischen Gründen abgelehnt. Der JVM-Betrieb bedeutet operativen Overhead der für eine einzelne Plattform dieser Größe schlicht nicht gerechtfertigt ist. Cluster-Komplexität war weit jenseits meiner Anforderungen. Und ich hatte kein Problem das verteilte Multi-Tenant-Analytik über Petabytes erfordert – ich hatte ein Problem mit zu langen Suchanfragen auf einer gewachsenen PHP-Plattform.
Was ich brauchte war Volltextsuche mit niedriger Latenz, Echtzeit-Updates ohne Merge-Overhead, vorhersehbares Memory-Verhalten und eine minimale operative Angriffsfläche. Manticore als aktiv entwickelter Fork von Sphinx erfüllte diese Anforderungen und erlaubte mir inkrementelle Evolution statt systemischen Ersatz. Das zählte in diesem Kontext mehr als Feature-Breite.
Der architektonische Reset
Die erste bewusste Entscheidung war aufzuhören den Index als Replik der relationalen Datenbank zu denken. In Sphinx war mein Schema schrittweise zu einem Spiegel der MySQL-Tabellen geworden. Das fühlte sich sicher an weil es vertraut war. Es war auch teuer weil jeder Such-Request Hydration-Logik und sekundäre Lookups auslöste die nichts mit der eigentlichen Suche zu tun hatten.
Mit Manticore behandelte ich den Index konsequent als Projektion optimiert für Retrieval. Menschenlesbare Herstellernamen wurden direkt im Dokument gespeichert statt nachträglich aufgelöst. Strukturierte Spezifikationen wurden geflattened. Der Publikationsstatus wurde direkt im Index gehalten. Alle filterbaren Attribute wurden explizit getypt. Das Ergebnis war ein Index ohne Post-Search-Joins und ohne Enrichment-Layer.
Denormalisierung erhöhte die Index-Größe – das war der bewusste Trade-off. Sie reduzierte die Request-Latenz um 40 bis 60 Millisekunden unter Last und eliminierte eine ganze Klasse von N+1-Problemen die sich über Monate eingeschlichen hatten. Die wichtige Verschiebung war dabei nicht technisch sondern konzeptuell. Suche ist kein Storage. Sie ist eine leseoptimierte materialisierte Sicht auf die Produktintention – und sollte auch so behandelt werden.
Von Batch-Indizierung zu Write-Through
Sphinx zwang mich zu einem Kompromiss aus Full-Rebuild, Delta-Index und periodischem Merge. Diese Merges waren die versteckte Steuer des Systems. Mit wachsendem Content-Volumen wuchs die Merge-Zeit proportional. Während Spitzen-Traffic wurde das zur echten Gefahr weil Merge-Operationen und hohe Query-Last um dieselben Ressourcen konkurrierten.
Mit Manticore RT-Tabellen wechselte ich zu Write-Through-Indizierung. Jeder erfolgreiche Datenbank-Write löste ein sofortiges Index-Update aus. Ich entschied mich bewusst für REPLACE statt INSERT weil es das Konsistenz-Modell vereinfachte ohne Diff-Logik oder bedingte Updates zu erfordern. Der Trade-off war höhere Write-Amplifikation und die Möglichkeit von Drift wenn der Search-Write fehlschlug – aber das war ein beherrschbares Problem, kein strukturelles.
Also machte ich Drift explizit statt es zu ignorieren. Ich führte eine asynchrone Retry-Queue ein, einen nächtlichen Abgleich der updated_at-Timestamps zwischen Datenbank und Index, und eine Freshness-Metrik die ich an Prometheus exportierte. Suche wurde damit bewusst eventual consistent – nicht aus Versehen sondern als bewusste Architekturentscheidung. Operativ entfernte das die gesamte Index-Merge-Angst. Keine Indizierungsfenster mehr um die Deployments koordiniert werden mussten. Das System wurde kontinuierlich statt episodisch.
Das gemessene Ergebnis
Vor der Migration lag die mediane Latenz bei etwa 5,1 Sekunden, P95 über 6 Sekunden. Reindex-Fenster blockierten schwere Writes für 12 bis 18 Minuten und mussten aktiv in den Deployment-Prozess eingeplant werden. Nach der Migration lag die mediane Latenz bei 82 Millisekunden, P95 bei 130 Millisekunden. Kein geplantes Reindex-Downtime mehr.
Die Verbesserung war keine Magie und kein Wunder der neuen Technologie. Es war das konsequente Entfernen von architektonischer Reibung. Die größten Gewinne kamen aus der Eliminierung von Delta-Merges und dem Entfernen der Post-Search-Hydration – zwei Probleme die durch falsche Grundannahmen über den Index entstanden waren, nicht durch die Technologie selbst.
Der schwierige Teil: Relevanz ist politisch
Performance-Probleme sind objektiv messbar und lassen sich mit Zahlen belegen. Relevanz-Probleme sind politisch – und das ist die unbequeme Wahrheit die kein Technologie-Artikel gerne schreibt.
Innerhalb einer Woche nach Go-Live kamen die ersten Beschwerden. Neue Einträge rankten nicht hoch genug. Exakte Modell-Matches tauchten unter generischen Artikeln auf. Manticore nutzt standardmäßig BM25 – eine solide Baseline die für viele Use Cases gut funktioniert, aber keine Produktprioritäten kennt und auch nicht kennen kann.
Ich brauchte Title-Matches die Body-Matches überwiegen, Exakt-Matches die partielle dominieren, einen leichten Recency-Bias für neue Inhalte und strikte Filterung auf den Publikationsstatus. Jede Anpassung verbesserte dabei einen Use Case und verschlechterte einen anderen. Erhöhter Recency-Bias verbesserte die Frische-Wahrnehmung bei aktuellen Modellen, degradierte aber historische Recherche-Queries. Starke Exakt-Match-Boosts sorgten dafür dass direkte Modellnamen dominierten, versteckten aber manchmal wertvolle kontextuelle Inhalte die Nutzer eigentlich suchten.
Der Durchbruch kam nicht durch eine bessere Formel sondern durch den Aufbau einer Relevanz-Regressions-Suite. 50 kanonische Queries, manuell definierte erwartete Top-Ergebnisse, automatisierter Vergleich vor jedem Deployment. Relevanz hörte damit auf meinungsgetrieben zu sein und wurde testbares Verhalten. Ohne diese Regressions-Tests sind Ranking-Anpassungen strukturiertes Glücksspiel – man verbessert etwas und weiß nicht was man dabei kaputt macht.
Der erste Production-Rückfall
Drei Monate nach dem Go-Live stieg die Latenz von 80 auf etwa 400 Millisekunden. Kein Traffic-Spike, keine Hardware-Änderung, kein offensichtlicher Auslöser. Die Ursache war ein neuer Filter auf einem High-Cardinality-String-Attribut für Motoren-Codes. Redakteure hatten angefangen inkonsistent zu taggen weil es keine Validierung gab. Was als strukturierter Filter gedacht war verhielt sich in der Praxis wie Semi-Freitext – mit entsprechenden Auswirkungen auf Query-Performance.
Die Behebung erforderte das String-Attribut durch ein normalisiertes Integer-Mapping zu ersetzen, den Index neu aufzubauen und Validierung am Write-Boundary durchzusetzen damit das Problem nicht wieder entstehen konnte. Die Lektion war unbequem aber klar. Such-Performance degradiert still und schrittweise wenn Schema-Disziplin erodiert – und Such-Infrastruktur verdient dieselbe Sorgfalt bei Schema-Änderungen wie relationale Datenbanken.
Manticore als Infrastruktur betreiben
Die erste Erkenntnis aus dem Betrieb war dass Relevanz-Regeln von Anfang an regressions-getestet werden müssen. Nicht erst wenn Stakeholder sich beschweren – sondern bevor das System live geht. Ranking-Änderungen ohne automatisierte Tests sind blind. Man weiß nicht was man verbessert und nicht was man dabei kaputt macht.
Die zweite Erkenntnis war dass Attribut-Typen am Write-Boundary erzwungen werden müssen. Nicht als nachträgliche Optimierung sondern als strukturelle Anforderung von Anfang an. Der Production-Rückfall drei Monate nach Go-Live wäre mit konsequenter Validierung am Eingang nicht passiert.
Die dritte Erkenntnis war dass Index-Freshness aktiv observierbar sein muss. Stillschweigende Annahmen über den Zustand eines Systems werden früher oder später falsch. Ich versionierte das Index-Schema in Git und behandelte Schema-Änderungen mit derselben Sorgfalt wie Datenbank-Migrationen: neuen Index erstellen, Backfill-Job ausführen, Traffic wechseln, alten Index droppen.
Zurück zum Ausgangspunkt
Die Fünf-Sekunden-Median-Latenz im Mai war kein temporärer Performance-Spike und kein zufälliges Ereignis. Es war ein architektonisches Signal das ich zu lange ignoriert hatte. Sphinx hatte seine operativen Grenzen in meinem spezifischen Usage-Pattern erreicht – nicht weil es eine schlechte Technologie ist sondern weil sich die Anforderungen verändert hatten ohne dass die Architektur mitgewachsen war.
Manticore erlaubte mir das Such-Subsystem grundlegend neu zu denken. Der Wechsel von Batch-Indizierung zu Write-Through, von einem relationalen Schema-Spiegel zu einer retrieval-optimierten Projektion, von impliziter zu expliziter Eventual Consistency – das waren die Entscheidungen die den Unterschied machten. Die Latenz sank von fünf Sekunden auf unter 100 Millisekunden.
Aber die eigentliche Veränderung war eine andere. Suche hörte auf ein fragiles Subsystem zu sein das ich umging und um das ich Deployments koordinieren musste – und wurde Infrastruktur die ich verstehe, messe und bewusst weiterentwickle.